
前々からXより告知されていた改定規約、仕様緩和が施行された。
主に、「機械学習・人工知能へのポスト情報の利用」「ブロック機能緩和」が挙げられる。

改定規約
施行された改定規約の内容については、
- Xのユーザーが自分のポストを世界中で閲覧可能にすることができる
- その代わりに、X社はそのポストの情報(テキスト、画像、動画、その他)を分析し、他の方法でXの向上に利用できる権利を有する
- 分析したものは、生成型か否かを問わずX社の機械学習・人工知能(AI)への使用・トレーニングに用いられる
となっており、また、
- 第三者の協力会社: お客様の設定に応じて、またはお客様がデータを共有している場合、当社はお客様の情報を第三者と共有したり、第三者に開示したりすることがあります。オプトアウトしない場合、情報の受信者は、Xのプライバシーポリシーに記載されている目的に加えて、たとえば、生成型か他のタイプかを問わず、人工知能モデルのトレーニングなど、独自の独立した目的のために情報を使用する場合があります。
とされている。
実際には、規約の改定内容が公開されるより前から、Xはポスト情報を機械学習等に用いる旨の内容を規約にしており、今回はその明文化となったという形。
基本的に、「設定ボタン」→「設定とプライバシー」→「プライバシーと安全」→「公開データに加えて、GrokおよびxAIでのやり取り、インプット、結果をトレーニングと調整に利用することを許可します」のチェックをオフにしておけば、機械学習に用いられることはないだろう。
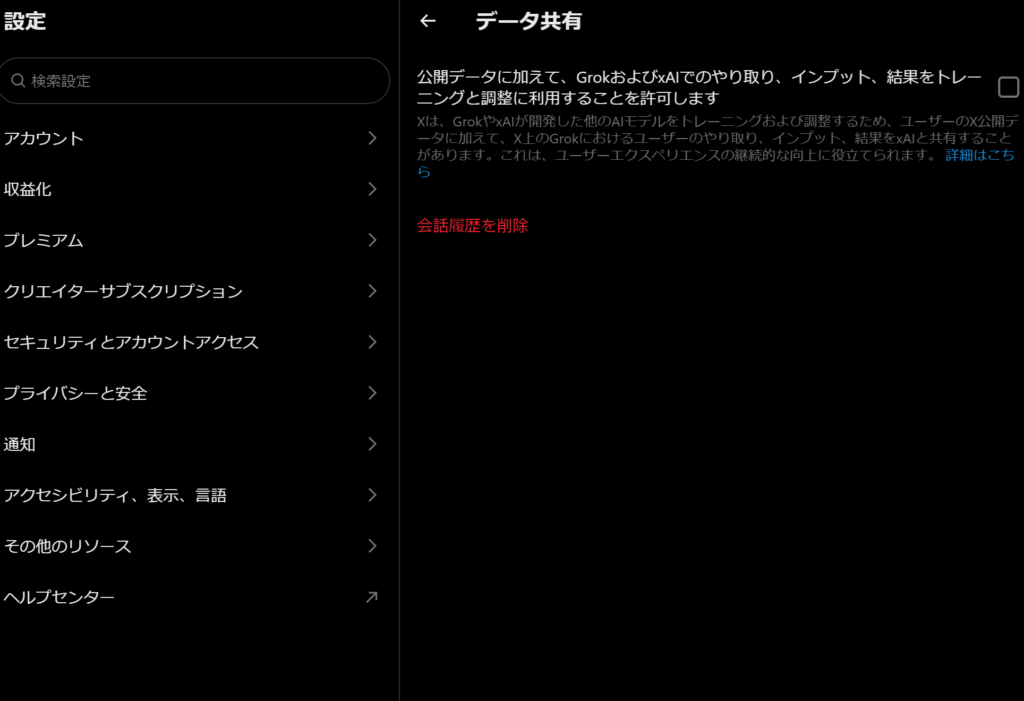
GrokはイーロンのAI企業であるxAI社が作ったAIだが、xAI社が作るそれ以外のAIにも、ポスト情報をトレーニング・調整に用いると記載されている。
改定規約施行前と表現がやや異なるが、意味は同じ。
ブロック機能の緩和
イーロン・マスクの「Xは対戦型SNSであるべき」という主張により、ブロック機能が下記の通りに緩和されている。
- ブロックされた相手アカウントは、ブロックを行ったアカウントのポストを見ることができる(リポスト、いいね、フォローなどのリアクションはできず、あくまで閲覧のみ可能)
- ブロックしたアカウントのポストが、Xの検索で表示される
ミュート機能との違いは、Xでの検索表示の可否、相手アカウントへのリアクションの可否となっている。
自分の場合、基本的には従来通りミュートを用いる予定。
イーロンの対戦型SNSであるべき、という主張に関しては自分は言論により多くの考えが集約されることから賛成の立場。
避難先に挙がったBluesky等
Xでポスト情報が機械学習に用いられることを拒絶し別SNSへ移ったり、YouTubeなどの動画サイトを主体にしようとするユーザー達が現れた。
Bluesky
頻繁に避難先候補として挙げられる、Xに酷似した後発SNSの「Bluesky」。
Xがイーロン・マスクに買収される前のTwitter時代にCEOを務め、シャドウバンや凍結で大暴れしていた「ジャック・ドーシー」らが経営している。
このBluesky、「ユーザーの投稿は機械学習等のAIに用いない」と発表しているが、これとは別にBlueskyの「robot.txt」では、GoogleやOpenAI、Baiduといったクローラー(WEBを自動巡回し情報を収集するロボット)の制限が殆どかからないように設定されている。
/* https://bsky.app/robots.txt */
# Hello Friends!
# If you are considering bulk or automated crawling, you may want to look in
# to our protocol (API), including a firehose of updates. See: https://atproto.com/
# By default, may crawl anything on this domain. HTTP 429 ("backoff") status
# codes are used for rate-limiting. Up to a handful concurrent requests should
# be ok.
User-Agent: *
Allow: //* https://bsky.social/robots.txt */
# Hello!
# Crawling the public API is allowed
User-agent: *
Allow: /ちなみにXのrobot.txtは次の通り。
/* https://x.com/robots.txt */
# Google Search Engine Robot
# ==========================
User-agent: Googlebot
Allow: /*?lang=
Allow: /hashtag/*?src=
Allow: /search?q=%23
Allow: /i/api/
Disallow: /search/realtime
Disallow: /search/users
Disallow: /search/*/grid
Disallow: /*?
Disallow: /*/followers
Disallow: /*/following
Disallow: /account/deactivated
Disallow: /settings/deactivated
Disallow: /[_0-9a-zA-Z]+/status/[0-9]+/likes
Disallow: /[_0-9a-zA-Z]+/status/[0-9]+/retweets
Disallow: /[_0-9a-zA-Z]+/likes
Disallow: /[_0-9a-zA-Z]+/media
Disallow: /[_0-9a-zA-Z]+/photo
User-Agent: Google-Extended
Disallow: *
User-Agent: FacebookBot
Disallow: *
User-agent: facebookexternalhit
Disallow: *
User-agent: Discordbot
Disallow: *
User-agent: Bingbot
Disallow: *
# Every bot that might possibly read and respect this file
# ========================================================
User-agent: *
Disallow: /ただ、AI企業はrobot.txtを無視して情報を収集する場合が多い。
とはいえ、クローラーをほぼすべて許可するというザル設定は通常のサイト運営でも滅多に見かけない。
(にしてもHello!って何だよ…)
また、Xは2023年2月2日に、APIの無料提供を停止し有料化したことで話題になっていた。
メディア等を含むポストの大量盗難はAPIを用いることで易化するが、現在のXではAPI利用には高額の使用料金が科されるのでAPIによる盗難を行いにくい状態になっている。
APIが使えない場合はSNSページのウェブスクレイピングを行うことになるが、こちらはAPI以上の手間がかかる。
その一方、BlueskyではAPIの制限がかけられていないため、APIを用いたメディア投稿の盗難のハードルがかなり低い。
前述の「robot.txt」を無視されていてもXの場合はAPIが有料であるためメディアコンテンツの大量盗難はされにくいのだが、APIが無料であるBlueskyは盗難の温床といっていい。
AIとの折り合い
現代・次代ではAIは色々なところで使われている
現代文明、及びこの先発展していく技術において、機械学習・人工知能は欠かせない。
肥大化していくコンテンツやサービスを向上させながら管理していくには人力では限界があり、必ずAIに頼る必要性が出てくる。
現時点でも、多くの企業は間接的にAIの恩恵を受けた上で成り立っており、日常において頻繁に用いる検索サービスなどでも機械学習が無くてはならない存在だ。
そういった次代の技術発展に対する機械学習に対しては、それほど血眼になって身構え反発しなくても良いように感じる。
問題なのは、そういった機械学習を悪用して盗難を図ろうとする行為であるが、現代のネット文明においてはどこかに投稿すれば必ずクローラーに収集されて学習に用いられる。
しかしそれは適切な技術発展という面では必要不可欠であり、例えば適切な技術の下で動画やイラストが収集されていかなければ、それらをWEB上でコンテンツとして認識することができなくなる。画像等を認識・学習することで成り立つGoogleの画像検索や動画検索、YouTubeなどが例として挙がる。
何だったら、有名なイラスト描画ソフトの1つであるPhotoshopを作っているAdobe社もAI推進派だし、それと双璧を成し大きなシェアを獲得しているCLIP STUDIO PAINTもAIを導入している。
ウォーターマークやノイズといった処理をかけても、原型が分からなくなるほどのものでなければ、近い将来にAIはそれらの処理を貫通して学習するだろう。
というより、既にそれらに対処できる手段もある程度存在する模様。
(ウォーターマークに関しては著作権侵害の可能性も生じるので、取り扱いは慎重にすべき)
ではどうすべきなのかというと、「自分が作った」ということを証明できればそれでいいと思える。
イラストであれば完成させた年月日と作成者をサインとして入れておいたり、動画であればクレジットを動画内に挿入しておけばいいのではないか。
つまり、ほぼ従来通りのやり方を貫いていけばいいと思っている。
悪意のある機械学習に対抗するため画像に大きな加工をかけて読み取りにくくすると、それは最早人間に向けた認識可能なコンテンツとは言い難い。
人のためではなく、対機械のために公開されているものという形になってしまい、これでは本末転倒である。
それどころか、正しい技術発展のための機械学習に支障が出てしまい、イラストや動画をそれらコンテンツとして認識できなくなっていく。
個人サイトを用いる選択
ただ、次代の発展を放置してでも機械学習に用いられることを拒絶するのであれば、まずSNSから立ち去るのが最適解であろう。
クロールされにくい閉じられた場所で個人のポートフォリオページを作れば、対策にはなる。ただ、それはクロールされない、発見されないことを前提条件とする。
それ以外の場合でも、今後のSNSの在り方を見ると個人サイトを所有し、いずれそちらをメインに据えることができるような体制を整えておくのも良いかもしれない。
昨今のSNS疲れ然り、将来的なSNSの価値観の変化然り、SNSに依存しない形の管理手段を有していて損ということはない。
現状でも個人サイトを運営するにあたり、機械学習に対し幾らかの防衛措置を行える。これはSNSを利用するうえでは実現できない防衛手段であり、今後のコードの進化によりさらなる防衛措置を講じることができるようになるとも考えられる。
総括
纏めると、個人的には下記のような認識・対応で良いと感じる。
- 現代ではネットに投稿すれば、ほぼ必ず機械学習に用いられる
- (1) 次代の技術発展において機械学習は欠かせない
- (2) 人に公開するのであれば人が認識しやすい形を設けるべき
- (3) その一方、悪意のある機械学習に対してはある程度対応する必要がある
- (1)~(3)を達成するためには、従来通りのサイン等を入れておき自分の著作物であることを証明する程度でいい(個人サイト等を持つ場合、その他の手法も考えられる)
- 機械学習を完全に拒絶するのであれば、隔離された個人ページを作って活動する
- いずれの場合でも、SNSタイプに依存しない個人サイトなどの手段は用意しておくといい

